
Introduction
In the note, a classifier of SVM(Support Vector Machine) and a classifier of CNN(Convolutional Neural Network) using transfer learning will be explored to experiment the accuracy of automatically classifying the image set of cats and dogs.
Method One
For the first method, an SVM classifier was trained to classify the images by families(family dog or family cat). SIFT will be applied to extracted the features from each image in the training set. Then the bag of word model will be applied to create a dictionary for these extracted features. This dictionary is formed by a clustering algorithm K-means. One cluster of features is viewed as a visual word in this dictionary. After the dictionary is created, images are represented by frequency vectors which represent the proportion of features belong to a visual word. Then, a SVM classifier is trained based on these frequency features.
Method Two
For the second method, we used CNN model to extracted features from the images. For this project, keras application are used. These applications are deep learning models with pre-trained weights. They can be used for prediction, feature extraction and fine tuning. The ResNet50, InceptionV3 and Xception model are used for extracting features from the images. Then these features will be used to trained a CNN model.
Data Set
The data set for this project is the provided by Microsoft Research and Kaggle. The training set consists of 25,000 images with half cat images and half dog images. The training set contains 12,500 images without labels. The size of these images are about $350\times 350$.
After downloading the image set from Kaggle, the images are separated into two folder, one for cat images, one for dog images. For dogs, the corresponding label is 1, for cats, the corresponding label is 0. The sample images in the data set are shown in the Figure 1. “Figure 1: images in data set”
“Figure 1: images in data set”
Process
Method One: Traditional Machine Learning Approach
For traditional image classification problems, features extracted by human are chosen to train classifiers. Then feature descriptors are use to represent the images. SIFT, HoG, RGB and HSV are the common features that are used to represent images.
For this project, SIFT are used to extracted the features and compute the feature descriptors. Because we know that the shapes of images of cat and dog are different with each other. Features extracted by SIFT will play an important role in the classification of the image set.
After implementing the SIFT algorithms to extract features, we get the features descriptors of all the images in the training set. K-means clustering algorithms is applied to generate a dictionary of visual words for the features descriptors in the training set. All the images are then represented by by frequency vectors which represent the proportion of features belong to a visual word.
Based on the frequency vectors generated by the BOW method, a SVM classifier was trained to make classification. The visualize process of this method is shown in the Figure 2.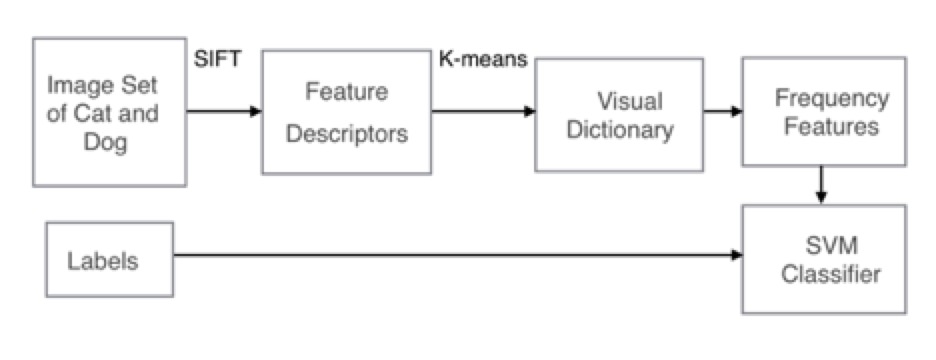 “Figure 2: Process of Method One”
“Figure 2: Process of Method One”
Source code for this method
The accuracy of this method is about $62\%$ when the images were compressed to $128 \times 128$, which is quite dissatisfactory for a binary classification problem. While when the images were compressed to $256 \times 256$, the accuracy only increase to $65.46\%$. “Result using Method One”
“Result using Method One”
Method Two: Deep Neural Netword(CNN with transfer learning)
Method two is refer to Peiwen Yang’s Post in Zhihu.
In Method Two, image features will be extracted by a Convolutional Neural Network model. After that, we can simply use dropout to classify the validation set and test set. Compared with the feature extraction by SIFT, convolutional neural network learn features from the images.
Several pre-trained model in keras application are used in this method to learn the features from the cat and dog image set. The ResNet50, InceptionV3 and Xception models are chosen to learn the features,which are object detection model in image recognition provided by keras. The weights of these models are pre-trained on ImageNet.
In order to improve the performance of the classification model, these three models are used together to learn the features from the images. These three models build up a huge network. If a fully connected layer is added directly after this huge network to train the classification model, the computation cost will be extremely large. Thus, the features extraction and classifier training are conducted separately. The pre-trained models are used to extract features. And then, these features are used to train the classifier.
For the trainning process, a simple neural network was used as the classification model, this model includes an input layer, a hidden layer with dropout rate $0.5$, and an output layer with sigmoid as activation function. The features number learned by each model is 2048, and then 6144 features was learned from the feature extraction process. The number of nodes in the input layer is 6144. For the hidden layer, there is also 6144 nodes, but they are not fully connected because dropout was applied in this layer. For the output layer, there is only 1 node because it is a binary classification problem.\newline
With fine features learning by pre-trained models, a simple model can make a good classification. The visualized process of this model is shown is Figure 3.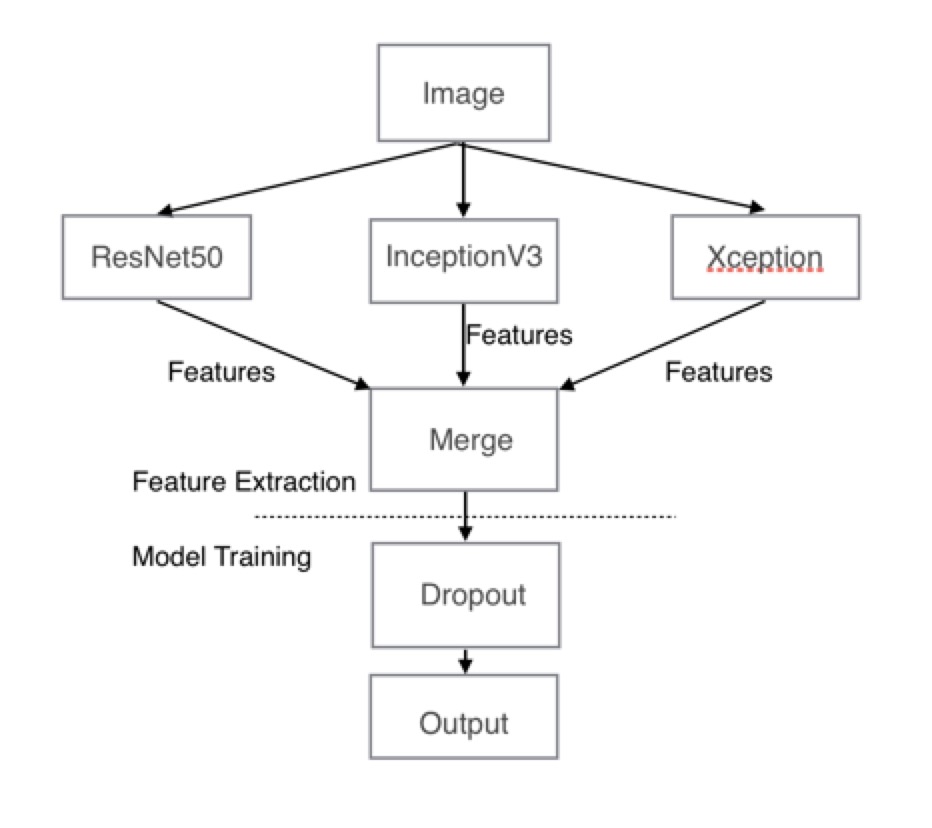 “Figure 3: Model of Method Two”
“Figure 3: Model of Method Two”
 “Result using Method two”
“Result using Method two”
In addition, the cost time of feature extraction for each model(ResNet50, InceptionV3 and Xception) is less than 20 minutes, which is also more efficient than the method one. Moreover, it only take less than 10 minutes to train the classifier.